Parameter estimation in PharmaPy
Learning objectives
After this section, you should be able to:
Identify main elements of batch reaction modeling, and construct PharmaPy objects necessary to run a batch reactor model in standalone mode
Recognize the importance of sensitivity calculations in dynamic parameter estimation
Compare optimization performance with original vs reparametrized reaction kinetics
Utilize python data structures and functions along with PharmaPy native objects
Contextualization
In this notebook, the syntax required to set a unit operation model in PharmaPy and then how to use it to perform parameter estimation will be shown.
The case study shown consists of multiple reactions in a batch reactor:

Reactor model
The batch reactor model solved by PharmaPy for this problem is a system ordinary differential equations (ODEs):
with reaction rates given by:
where \(\mathcal{R_i}\) is the set of reactants of reaction \(i\) (e.g. \(\mathcal{R}_3 = \{B\}\)). The temperature-dependent coefficient \(k_i\) is given by an Arrhenius expression:
In order to simulate a batch reactor in PharmaPy, three objects are required:
Reactor: instance containing the unit operation model, Eq. \eqref{eq:dC_dt}
Phase object: instance representing the initial liquid load in the reactor
Kinetic object: instance that receives reaction rate parameters and calls methods to calculate reaction rates, Eqs. \eqref{eq:rate_eqn}-\eqref{eq:ki_temp}
First, the corresponding PharmaPy classes are called:
[1]:
from PharmaPy.Phases import LiquidPhase
from PharmaPy.Kinetics import RxnKinetics
from PharmaPy.Reactors import BatchReactor
Could not find GLIMDA.
Then, a liquid phase is specified, which requires the path to a property file that contains pure-component information for all the chemical species (in this case the json file pointed by the path_pure variable) used in the simulation. Since the pure-component file has 5 species, composition information will be of size 5.
Reaction kinetics receives the path json file, and the reaction network, which can be passed as a list of strings. PharmaPy uses this list to construct the stoichiometric matrix of the reaction network. Moreover, some reaction parameter values are provided for reference. Note that \(T_{ref}\) in Eq. (4) is not passed to the RxnKinetics class, which makes PharmaPy to use infinite as default (non-centered version).
In order to retrieve the documentation of any PharmaPy class or method (i.e. list and description of the mandatory and optional arguments that the class or method takes), use the key combination Shift + Tab. For instance, to toggle the documentation of the PharmaPy LiquidPhase class below, start by writting LiquidPhase( and then use the key combination mentioned before.
[2]:
reactor = BatchReactor()
path_pure = '../data/pure_components_ziegler.json'
liquid = LiquidPhase(path_pure, temp=673, mole_conc=[1, 0, 0, 0, 0], name_solv='solvent')
rxns = ['A --> B', 'A --> C', 'B --> C', 'B --> D']
k_vals = [0.1] * 4
ea_vals = [0] * 4
kin = RxnKinetics(path_pure, rxn_list=rxns, k_params=k_vals, ea_params=ea_vals)
Once phase and kinetic objects are created, they are aggretated to the reactor instance using the dot syntax:
[3]:
reactor.Phases = liquid
reactor.Kinetics = kin
Now, the reactor model can be solved in standalone mode. The eval_sens=True flag will be passed to the solving method in order to compute the sensitivity system of the reaction model. Sensitivity \(\mathbf{S}\) indicates at which extent the states of the dynamic system (in this case molar concentrations \(C_j\)) depend on the parameters (\(\theta_p\)).
Sensitivities \(\mathbf{S}\) are internally passed to the parameter estimation framework of PharmaPy to guide the parameter search. To understand this, let’s recall the objective function of the parameter estimation problem:
The required gradient to guide the optimizer search is:
which is calculated using \(\mathbf{S}(t)\).
The sensitivty system is solved along the original ODE system describing the batch reactor. For completeness, a convenience plot function plot_profiles allows to check representative results from the model.
[4]:
time, states, sens = reactor.solve_unit(runtime=120, eval_sens=True) # run for 2 minutes
Final Run Statistics: ---
Number of steps : 99
Number of function evaluations : 124
Number of Jacobian evaluations : 2
Number of function eval. due to Jacobian eval. : 0
Number of error test failures : 1
Number of nonlinear iterations : 121
Number of nonlinear convergence failures : 0
Number of sensitivity evaluations : 124
Number of function eval. due to sensitivity eval. : 0
Number of sensitivity error test failures : 0
Sensitivity options:
Method : SIMULTANEOUS
Difference quotient type : CENTERED
Suppress Sens : False
Solver options:
Solver : CVode
Linear multistep method : BDF
Nonlinear solver : Newton
Linear solver type : DENSE
Maximal order : 5
Tolerances (absolute) : 1e-06
Tolerances (relative) : 1e-06
Simulation interval : 0.0 - 120.0 seconds.
Elapsed simulation time: 0.020591700000000213 seconds.
[5]:
reactor.plot_profiles(figsize=(12, 3))
[5]:
(<Figure size 1200x300 with 4 Axes>,
array([<AxesSubplot: ylabel='$C_{j}$ ($\\mathregular{mol \\ L^{-1}}$)'>,
<AxesSubplot: ylabel='$T$ ($\\mathregular{K}$)'>,
<AxesSubplot: ylabel='$Q_{rxn}$ ($\\mathregular{W}$)'>],
dtype=object))

The sensitivity system can also be plotted as
[6]:
reactor.plot_sens()
[6]:
(<Figure size 600x857.143 with 8 Axes>,
array([[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial k_1}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial k_2}$'>],
[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial k_3}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial k_4}$'>],
[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial E_{a, 1}}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial E_{a, 2}}$'>],
[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial E_{a, 3}}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial E_{a, 4}}$'>]],
dtype=object))

Available results can be inspected by printing the results instance of the reactor object. Also, its attributes can be used in further calculations as any python object.
[7]:
print(reactor.result)
------------------------
PharmaPy result object
------------------------
Fields shown in the tables below can be accessed as result.<field>, e.g. result.mole_conc
---------------------------------------
states dim units index
---------------------------------------
mole_conc 4 mol/L A, B, C, D
---------------------------------------
------------------------------
f(states) dim units index
------------------------------
q_rxn 1 W
q_ht 1 W
temp 1 K
------------------------------
Time vector can be accessed as result.time
Parameter estimation procedure
The ultimate goal is to determine the reaction parameters \(A_i\) and \(E_i\) (\(i = [1, 2, 3, 4]\)) for each one of the reactions. For this purpose, time-dependent \(B\) and \(C\) concentration datasets are available at different temperatures.
The approach shown in this notebook has two stages. In the first stage, parameter estimates are found for each isothermal dataset on an individual basis. Then, these parameter estimates are used as seed values in the second stage, where the all the datasets are used simultaneously to obtain representative parameter estimates and confidence intervals.
First stage: Isothermal fitting
Individual parameter estimation procedures are performed on each isothermal concentration dataset. Each estimation will yield estimates of \(A_i\) (or \(log(A_i)\)) for all reactions at a given temperature. For this reason, the non-linear regression in PharmaPy will not yield \(E_i\) estimates in this first stage. After \(k_i\) values are individually obtained by non-linear optimization, estimates of \(E_i\) are calculated by linear regression.
An additional feature of PharmaPy will be used for parameter estimation in batch reactors. A reformulation of the temperature-dependent term in the kinetic model (Eq. 3) is available in PharmaPy, and can be activated by passing the keyword argument reformulate_kin=True to the RxnKinetics class. The reformulation has the form:
with the reformulated parameters:
Under this reparametrization, the new parameter set is \(\theta_p = \{\varphi_{1, 1}, \cdots, \varphi_{1, 4}, \varphi_{2, 1}, \cdots \varphi_{2, 4} \}\). This reformulation brings the estimated parameters and corresponding sensitivities to a closer order of magnitude compared to their original values, making the solution of the parameter estimation problem more numerically stable.
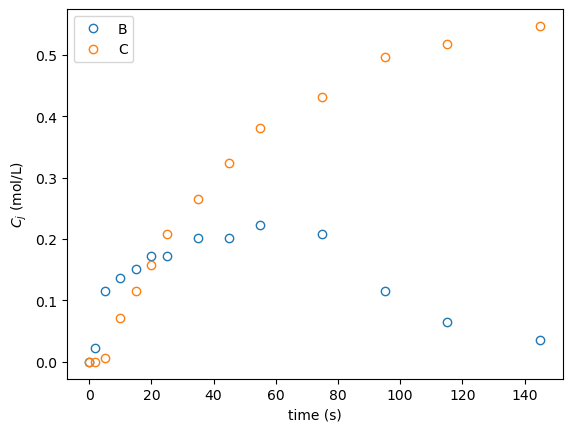
As a sanity check, one dataset from the available data can be plotted:
[8]:
import numpy as np
import matplotlib.pyplot as plt
# Let's import one of the datasets
data = np.genfromtxt('../data/ziegler_data_673K.csv', delimiter=',')
t_exp = data[:, 0]
c_exp = data[:, 1:]
print(t_exp.shape, c_exp.shape)
plt.plot(t_exp, c_exp, 'o', mfc='None')
plt.xlabel('time (s)')
plt.ylabel('$C_j$ (mol/L)')
plt.legend(('B', 'C'))
(14,) (14, 2)
[8]:
<matplotlib.legend.Legend at 0x287a63ed280>
In order to allow parameter estimation, a simulation object needs to be created. Then, a fully-specified reactor object is aggregated to it, which enables optimization. Because simulation objects can contain one or more unit operations, the connectivity of the flowsheet has to be passed as a string through the flowsheet argument.
[9]:
from PharmaPy.SimExec import SimulationExec
import numpy as np
import copy
import json
# Initial concentration
with open('../data/ziegler_conc_init.json') as f:
c_init = json.load(f)
sim = SimulationExec(path_pure, flowsheet='R01')
reactor = BatchReactor()
kin = RxnKinetics(path_pure, rxn_list=rxns, k_params=k_vals, ea_params=ea_vals, temp_ref=723, reformulate_kin=True)
kin_seed = copy.deepcopy(kin)
liquid = LiquidPhase(path_pure, mole_conc=c_init['673K'], name_solv='solvent')
reactor.Kinetics = kin
reactor.Phases = liquid
sim.R01 = reactor # The aggregated instance has to have the same name as the names passed to `sim` through the 'flowsheet' argument
param_bools = [True] * 4 + [False] * 4 # (only k_i's are estimated)
sim.SetParamEstimation(x_data=t_exp, y_data=c_exp, measured_ind=(1, 2), optimize_flags=param_bools)
k_estimated, covar, info_di = sim.EstimateParams()
print(sim.ParamInst.paramest_df)
------------------------------------------------------------
eval fun_val ||step|| gradient dampening_factor
------------------------------------------------------------
0 2.405e+00 --- 1.191e+00 3.529e-03
1 4.506e-01 2.874e+00 3.891e-01 1.246e-03
2 2.045e-02 2.825e+00 4.999e-02 4.154e-04
3 9.994e-03 2.770e-01 3.622e-03 1.385e-04
4 9.900e-03 4.018e-02 1.204e-04 4.615e-05
5 9.900e-03 2.421e-03 2.199e-06 1.538e-05
6 9.900e-03 6.168e-05 5.942e-08 5.128e-06
7 9.900e-03 2.158e-06 5.942e-08 1.026e-05
8 9.900e-03 2.157e-06 5.942e-08 4.103e-05
9 9.900e-03 2.152e-06 5.942e-08 3.282e-04
10 9.900e-03 2.105e-06 5.942e-08 5.251e-03
11 9.900e-03 1.563e-06 5.942e-08 1.680e-01
12 9.900e-03 2.604e-07 5.942e-08 1.075e+01
------------------------------------------------------------
Optimization time: 1.80e-01 s.
obj_fun \varphi_{1, 1} \varphi_{1, 2} \varphi_{1, 3} \varphi_{1, 4}
0 2.405431 -2.302585 -2.302585 -2.302585 -2.302585
1 0.450650 -3.623486 -3.600098 -4.333372 -1.461591
2 0.020447 -4.400277 -4.694309 -4.615062 -3.931676
3 0.009994 -4.136805 -4.723977 -4.567379 -3.996344
4 0.009900 -4.165404 -4.725049 -4.595061 -4.001763
5 0.009900 -4.165386 -4.724137 -4.597293 -4.001548
6 0.009900 -4.165415 -4.724127 -4.597343 -4.001569
7 0.009900 -4.165415 -4.724126 -4.597344 -4.001569
8 0.009900 -4.165415 -4.724126 -4.597344 -4.001569
9 0.009900 -4.165415 -4.724126 -4.597344 -4.001569
10 0.009900 -4.165415 -4.724126 -4.597344 -4.001569
11 0.009900 -4.165415 -4.724127 -4.597344 -4.001569
12 0.009900 -4.165415 -4.724127 -4.597343 -4.001569
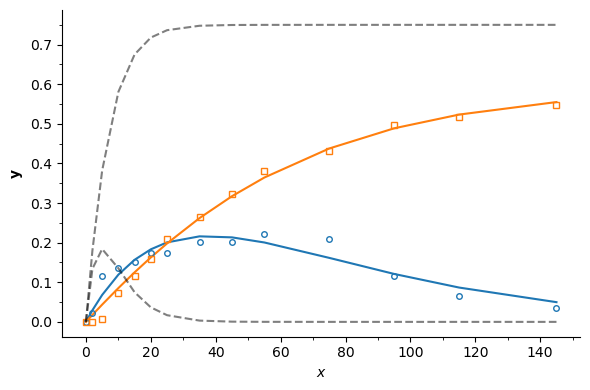
Data vs model prediction can be plotted to visually inspect the quality of the fit. Additionally, the prediction of the model with the seed parameters can also be included for completeness. Note that the sensitivities are now with respect to the reparametrized kinetics (\(\varphi_{1,i}\) and \(\varphi_{2,i}\))
[10]:
fig, axis = sim.ParamInst.plot_data_model(figsize=(6, 4))
reactor.plot_sens()
# Simulate the system with the parameter seeds and plot
reactor.reset()
reactor.Kinetics = kin_seed
reactor.solve_unit(time_grid=t_exp, verbose=False)
axis.plot(reactor.result.time, reactor.result.mole_conc[:, [1, 2]], 'k--', alpha=0.5)
[10]:
[<matplotlib.lines.Line2D at 0x287a82d0820>,
<matplotlib.lines.Line2D at 0x287a82d0940>]

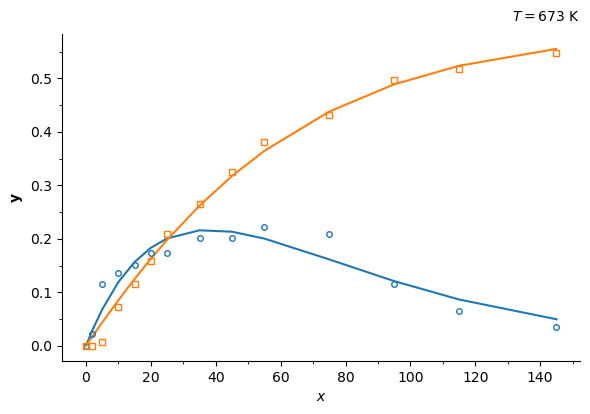
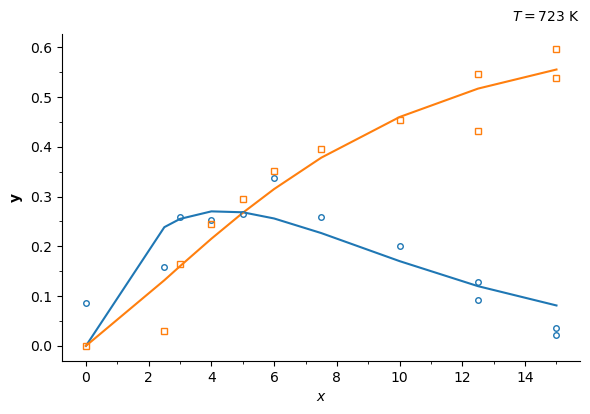
Now, let’s calculate the parameters for all the available datasets, one at a time. The available datasets can be seen under ../data/ziegler_data_XK where X is the temperature in K. We will use string contatenation syntax 'name_%i' % val, where val is inserted in the string, being val of the integer datatype (e.g. if val = 300, then the string concatenation above will yield 'name_300'.
[11]:
temps = np.array([673, 698, 723, 748, 773]) # available temperatures
lnA_estimated = {}
param_bools = [True] * 4 + [False] * 4 # (only k_i's are estimated)
plot = True
for ind, temp in enumerate(temps):
data = np.genfromtxt('../data/ziegler_data_%iK.csv' % temp, delimiter=',')
t_exp = data[:, 0]
c_exp = data[:, 1:]
sim = SimulationExec(path_pure, flowsheet='R01')
reactor = BatchReactor()
kin = RxnKinetics(path_pure, rxn_list=rxns, k_params=k_vals, ea_params=ea_vals, reformulate_kin=True)
liquid = LiquidPhase(path_pure, temp=temp, mole_conc=[1, 0, 0, 0, 0], name_solv='solvent')
reactor.Kinetics = kin
reactor.Phases = liquid
sim.R01 = reactor
sim.SetParamEstimation(x_data=t_exp, y_data=c_exp, measured_ind=(1, 2), optimize_flags=param_bools)
lnA_estim, covar, info_di = sim.EstimateParams()
lnA_estimated[temp] = lnA_estim
if plot:
fig, axis = sim.ParamInst.plot_data_model(figsize=(6, 4))
axis.text(1, 1.04, '$T = %i$ K' % temp, transform=axis.transAxes, fontsize=10, ha='right')
------------------------------------------------------------
eval fun_val ||step|| gradient dampening_factor
------------------------------------------------------------
0 2.405e+00 --- 1.191e+00 3.529e-03
1 4.506e-01 2.874e+00 3.891e-01 1.246e-03
2 2.045e-02 2.825e+00 4.999e-02 4.154e-04
3 9.994e-03 2.770e-01 3.622e-03 1.385e-04
4 9.900e-03 4.018e-02 1.204e-04 4.615e-05
5 9.900e-03 2.421e-03 2.199e-06 1.538e-05
6 9.900e-03 6.168e-05 5.942e-08 5.128e-06
7 9.900e-03 2.158e-06 5.942e-08 1.026e-05
8 9.900e-03 2.157e-06 5.942e-08 4.103e-05
9 9.900e-03 2.152e-06 5.942e-08 3.282e-04
10 9.900e-03 2.105e-06 5.942e-08 5.251e-03
11 9.900e-03 1.563e-06 5.942e-08 1.680e-01
12 9.900e-03 2.604e-07 5.942e-08 1.075e+01
------------------------------------------------------------
Optimization time: 1.73e-01 s.
------------------------------------------------------------
eval fun_val ||step|| gradient dampening_factor
------------------------------------------------------------
0 1.072e+00 --- 7.645e-01 4.130e-03
1 1.022e-01 2.258e+00 1.382e-01 1.377e-03
2 2.595e-01 1.849e+00 1.382e-01 2.754e-03
3 1.241e-01 1.456e+00 1.382e-01 1.101e-02
4 4.795e-02 7.636e-01 5.534e-02 3.671e-03
5 3.946e-02 6.142e-01 4.731e-02 3.628e-03
6 3.417e-02 1.435e-01 1.934e-03 1.209e-03
7 3.415e-02 3.124e-02 1.561e-04 4.031e-04
8 3.415e-02 1.581e-03 7.957e-06 1.344e-04
9 3.415e-02 1.294e-04 1.073e-06 1.283e-04
10 3.415e-02 1.817e-05 1.544e-07 4.278e-05
11 3.415e-02 2.703e-06 1.544e-07 8.556e-05
12 3.415e-02 2.698e-06 1.544e-07 3.422e-04
13 3.415e-02 2.672e-06 1.544e-07 2.738e-03
14 3.415e-02 2.464e-06 1.544e-07 4.381e-02
15 3.415e-02 1.317e-06 1.544e-07 1.402e+00
16 3.415e-02 1.033e-07 1.544e-07 8.971e+01
------------------------------------------------------------
Optimization time: 2.28e-01 s.
------------------------------------------------------------
eval fun_val ||step|| gradient dampening_factor
------------------------------------------------------------
0 2.385e-01 --- 3.464e-01 5.723e-03
1 7.299e-02 8.369e-01 9.598e-02 2.896e-03
2 5.360e-02 2.918e-01 3.197e-03 9.655e-04
3 5.345e-02 9.450e-02 1.607e-03 4.979e-04
4 5.344e-02 8.019e-03 6.870e-05 1.660e-04
5 5.344e-02 1.156e-03 1.103e-05 1.239e-04
6 5.344e-02 1.786e-04 1.793e-06 4.130e-05
7 5.344e-02 2.983e-05 2.956e-07 6.067e-05
8 5.344e-02 5.015e-06 4.882e-08 2.022e-05
9 5.344e-02 8.310e-07 4.882e-08 4.044e-05
10 5.344e-02 8.302e-07 4.882e-08 1.618e-04
11 5.344e-02 8.254e-07 4.882e-08 1.294e-03
12 5.344e-02 7.853e-07 4.882e-08 2.071e-02
13 5.344e-02 5.214e-07 4.882e-08 6.626e-01
14 5.344e-02 6.343e-08 4.882e-08 4.241e+01
------------------------------------------------------------
Optimization time: 1.65e-01 s.
------------------------------------------------------------
eval fun_val ||step|| gradient dampening_factor
------------------------------------------------------------
0 1.597e-01 --- 8.458e-02 5.139e-03
1 1.269e-01 1.963e+00 1.266e-01 5.376e-03
2 5.160e-02 8.681e-01 1.609e-02 1.850e-03
3 5.146e-02 6.593e-01 4.924e-02 3.397e-03
4 4.732e-02 1.916e-01 1.439e-03 1.132e-03
5 4.712e-02 2.912e-01 5.402e-03 1.064e-03
6 4.702e-02 1.507e-01 8.423e-04 3.545e-04
7 4.698e-02 1.954e-01 1.518e-03 2.556e-04
8 4.697e-02 1.098e-01 3.688e-04 8.521e-05
9 4.697e-02 8.863e-02 2.450e-04 3.937e-05
10 4.697e-02 2.908e-02 2.374e-05 1.312e-05
11 4.697e-02 5.066e-03 2.070e-06 4.375e-06
12 4.697e-02 6.489e-05 2.926e-07 1.458e-06
13 4.697e-02 4.370e-05 2.926e-07 2.916e-06
14 4.697e-02 4.328e-05 2.926e-07 1.167e-05
15 4.697e-02 4.094e-05 2.926e-07 9.332e-05
16 4.697e-02 2.726e-05 2.926e-07 1.493e-03
17 4.697e-02 5.080e-06 2.926e-07 4.778e-02
18 4.697e-02 1.877e-06 2.926e-07 3.058e+00
19 4.697e-02 8.623e-08 2.617e-07 1.891e+02
------------------------------------------------------------
Optimization time: 2.32e-01 s.
------------------------------------------------------------
eval fun_val ||step|| gradient dampening_factor
------------------------------------------------------------
0 4.085e-01 --- 2.461e-01 2.242e-03
1 1.716e-01 3.238e+00 7.526e-02 2.065e-03
2 1.004e-01 2.583e+00 6.215e-02 2.065e-03
3 5.623e-02 1.842e+00 4.400e-02 1.969e-03
4 5.381e-02 1.113e+00 1.080e-01 3.107e-03
5 2.486e-02 2.802e-01 4.389e-03 1.036e-03
6 2.476e-02 6.793e-02 5.498e-04 3.452e-04
7 2.476e-02 6.916e-03 7.088e-06 1.151e-04
8 2.476e-02 1.525e-04 8.725e-08 6.903e-05
9 2.476e-02 3.695e-06 1.150e-08 2.301e-05
10 2.476e-02 6.990e-07 1.150e-08 4.602e-05
11 2.476e-02 6.967e-07 1.150e-08 1.841e-04
12 2.476e-02 6.832e-07 1.150e-08 1.473e-03
13 2.476e-02 5.803e-07 1.150e-08 2.356e-02
14 2.476e-02 1.964e-07 1.150e-08 7.540e-01
------------------------------------------------------------
Optimization time: 1.66e-01 s.


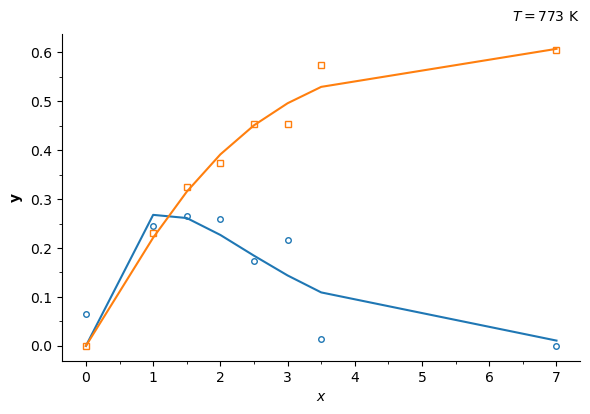
The collected parameters in the dictionary k_estimated can be conveniently stacked in a pandas dataframe:
[12]:
import pandas as pd
param_summary = pd.DataFrame.from_dict(lnA_estimated, orient='index', columns=sim.ParamInst.name_params[:4])
print(param_summary)
\varphi_{1, 1} \varphi_{1, 2} \varphi_{1, 3} \varphi_{1, 4}
673 -4.165415 -4.724127 -4.597343 -4.001569
698 -2.739370 -3.852349 -3.117100 -3.141693
723 -1.773407 -3.134609 -2.036008 -2.145335
748 -1.118855 -4.518830 -0.974391 -1.634199
773 -0.457933 -1.542751 -0.862445 -0.796216
Note that, since we passed the reformulate_model=True flag to the kinetics class, the data collected in the param_summary variable are \(\ln(k_i)\) at the given temperatues. A linearized version of Eq. (4) can be written:
which allows to find pre-exponential factors \(A_i\) and activation energies \(E_i\) estimates by performing linear regression of \(\ln(k_i)\) vs \(1/T\) data. We can do so in a foor loop again. Plots of the data vs the linear model can be generated to visually inspect the goodness of fit for stage one
[13]:
from scipy.stats import linregress
def linear_model(x, sl, interc): return sl * x + interc
ln_A = []
Ea_R = []
fig_lin, ax_lin = plt.subplots(2, 2, figsize=(8, 7))
ax_flat = ax_lin.flatten()
for ind, col in enumerate(param_summary.values.T):
# Perform linear regression
x = 1 / temps
y = col
res = linregress(x, y) #
ln_A.append(res.intercept)
Ea_R.append(-res.slope)
# Plot
ax = ax_flat[ind]
ax.plot(1000*x, y, 'o', mfc='None') # Data
model = linear_model(x, res.slope, res.intercept)
ax.plot(1000*x, model, '--')
fig_lin.text(0, 0.5, '$\ln(k_i)$', rotation=90, va='center')
fig_lin.text(0.5, 0, '$1000/T$')
[13]:
Text(0.5, 0, '$1000/T$')
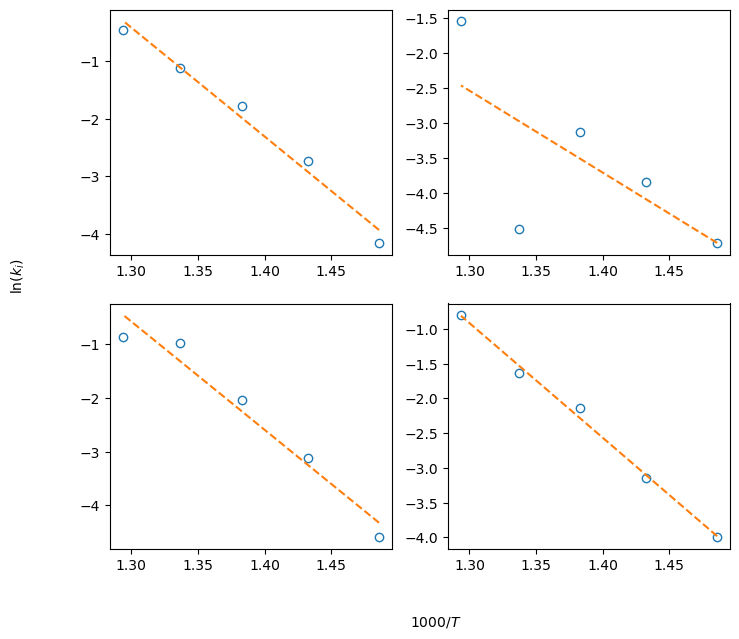
The final results can be collected into a pandas dataframe:
[14]:
seed_linear = pd.DataFrame({'ln_A': ln_A, 'Ea/R': Ea_R}, index=rxns)
print(seed_linear)
ln_A Ea/R
A --> B 24.177763 18917.969625
A --> C 12.672033 11703.706227
B --> C 25.661558 20180.373959
B --> D 20.532433 16499.900820
Second stage: Simultaneous estimation
For this purpose, all datasets will be passed at once to the SetParameterEstimation method, instead of one at a time. Datasets will be collected into dictionaries first.
[15]:
x_data = {}
y_data = {}
phase_modif = {}
for ind, temp in enumerate(temps):
# Data
data = np.genfromtxt('../data/ziegler_data_%iK.csv' % temp, delimiter=',')
t_exp = data[:, 0]
c_exp = data[:, 1:]
exp_name = '%.0fK' % temp
x_data[exp_name] = t_exp
y_data[exp_name] = c_exp
phase_modif[exp_name] = {'temp': temp, 'mole_conc': c_init['%iK' % temp]}
Then, new PharmaPy objects (reactor, kinetics and phase) can be created. The parameters found by linear regression in the first stage will be used as seeds for the parameter estimation instance. The keyword argument reformulate_kin=True will be also passed for simultaneous parameter estimation.
[16]:
k_seed = np.exp(seed_linear['ln_A'].values)
ea_seed = 8.314 * seed_linear['Ea/R'].values
## Uncomment the following two lines and evaluate optimization performance
# k_seed = [1e5] * 4
# ea_seed = [1e5] * 4
temp_mean = np.mean(temps)
reformulate = True # Try with False and compare optimizer performance and parameter estimates
if not reformulate:
temp_mean = None
kin_rxn = RxnKinetics(path_pure, rxn_list=rxns, k_params=k_seed, ea_params=ea_seed,
reformulate_kin=reformulate, temp_ref=temp_mean)
liquid = LiquidPhase(path_pure, **phase_modif['698K'], name_solv='solvent')
sim = SimulationExec(path_pure, 'R01')
sim.R01 = BatchReactor()
sim.R01.Kinetics = kin_rxn
sim.R01.Phases = liquid
Parameter estimation is called again, this time with data structures that contain all the datasets simulataneously. After solving the problem, a ParamInst object within the sim instance is available, which enables more functionalities
[17]:
sim.SetParamEstimation(x_data=x_data, y_data=y_data, measured_ind=(1, 2), phase_modifiers=phase_modif)
optimopts = {'eps_1': 1e-11, 'eps_2': 1e-11}
optim_params, hessian_inv, info = sim.EstimateParams(optim_options=optimopts)
fig, axis = sim.ParamInst.plot_data_model(figsize=(7, 7))
------------------------------------------------------------
eval fun_val ||step|| gradient dampening_factor
------------------------------------------------------------
0 2.639e-01 --- 2.370e-01 2.489e-02
1 2.223e-01 4.831e-01 1.236e-01 2.259e-02
2 2.172e-01 1.610e-01 3.469e-02 2.237e-02
3 2.166e-01 1.623e-01 3.012e-02 3.026e-02
4 2.169e-01 1.473e-01 3.012e-02 6.052e-02
5 2.159e-01 1.076e-01 2.053e-02 7.166e-02
6 2.155e-01 5.188e-02 6.129e-03 7.166e-02
7 2.155e-01 2.046e-02 2.628e-03 7.203e-02
8 2.155e-01 8.979e-03 1.084e-03 7.218e-02
9 2.155e-01 3.927e-03 4.597e-04 7.241e-02
10 2.155e-01 1.627e-03 1.978e-04 7.241e-02
11 2.155e-01 8.082e-04 8.506e-05 7.241e-02
12 2.155e-01 3.515e-04 3.896e-05 7.026e-02
13 2.155e-01 2.192e-04 1.887e-05 6.600e-02
14 2.155e-01 1.191e-04 1.030e-05 3.647e-02
15 2.155e-01 1.164e-04 6.681e-06 3.230e-02
16 2.155e-01 5.581e-05 5.291e-06 2.817e-02
17 2.155e-01 4.623e-05 4.633e-06 4.217e-02
18 2.155e-01 2.798e-05 3.802e-06 4.217e-02
19 2.155e-01 2.173e-05 3.802e-06 8.434e-02
20 2.155e-01 1.503e-05 1.631e-06 1.133e-01
21 2.155e-01 3.912e-06 4.110e-07 4.377e-02
22 2.155e-01 3.001e-06 4.110e-07 8.753e-02
23 2.155e-01 1.885e-06 4.110e-07 3.501e-01
24 2.155e-01 6.146e-07 1.895e-07 1.167e-01
25 2.155e-01 1.250e-06 1.895e-07 2.334e-01
26 2.155e-01 6.972e-07 1.895e-07 9.337e-01
27 2.155e-01 1.922e-07 1.781e-07 3.112e-01
28 2.155e-01 5.157e-07 1.781e-07 6.225e-01
29 2.155e-01 2.705e-07 1.781e-07 2.490e+00
30 2.155e-01 7.039e-08 1.750e-07 1.635e+00
31 2.155e-01 1.047e-07 1.707e-07 1.859e+00
32 2.155e-01 9.011e-08 1.672e-07 3.086e+00
33 2.155e-01 5.356e-08 1.651e-07 5.177e+00
34 2.155e-01 3.168e-08 1.651e-07 1.035e+01
35 2.155e-01 1.589e-08 1.651e-07 4.142e+01
36 2.155e-01 3.983e-09 1.651e-07 3.313e+02
37 2.155e-01 4.982e-10 1.651e-07 5.301e+03
------------------------------------------------------------
Optimization time: 2.58e+00 s.

Different statistics such as confidence intervals can be generated by creating a statistics instance from the simulation object:
[18]:
stats = sim.CreateStatsObject(alpha=0.95)
intervals = stats.get_intervals()
----------------------------------------------------------------------------------------------------
param lb mean ub 95% CI (+/-) 95% CI (+/- %)
----------------------------------------------------------------------------------------------------
\varphi_{1, 1} -2.177e+00 -2.022e+00 -1.867e+00 1.549e-01 7.66361
\varphi_{1, 2} -3.754e+00 -3.332e+00 -2.909e+00 4.228e-01 12.69212
\varphi_{1, 3} -2.401e+00 -2.152e+00 -1.903e+00 2.490e-01 11.56767
\varphi_{1, 4} -2.445e+00 -2.301e+00 -2.158e+00 1.437e-01 6.24629
\varphi_{2, 1} 9.690e+00 9.807e+00 9.924e+00 1.170e-01 1.19322
\varphi_{2, 2} 9.375e+00 9.688e+00 1.000e+01 3.125e-01 3.22595
\varphi_{2, 3} 9.591e+00 9.770e+00 9.948e+00 1.781e-01 1.82350
\varphi_{2, 4} 9.552e+00 9.683e+00 9.814e+00 1.312e-01 1.35473
----------------------------------------------------------------------------------------------------
Now let’s run some of the models at the optimum parameter values and check the sensitivity system
[19]:
if reformulate:
ea_optim = np.exp(optim_params[4:]) * 8.314
k_optim = np.exp(ea_optim/8.314/temp_mean + optim_params[:4])
else:
k_optim = optim_params[:4]
ea_optim = optim_params[4:]
kin_rxn = RxnKinetics(path_pure, rxn_list=rxns, k_params=k_optim, ea_params=ea_optim,
reformulate_kin=reformulate, temp_ref=temp_mean)
temp_str = '698K'
liquid = LiquidPhase(path_pure, **phase_modif[temp_str], name_solv='solvent')
reactor = BatchReactor()
reactor.Kinetics = kin_rxn
reactor.Phases = liquid
time, states, sens = reactor.solve_unit(runtime=x_data[temp_str][-1], eval_sens=True)
Final Run Statistics: ---
Number of steps : 76
Number of function evaluations : 104
Number of Jacobian evaluations : 2
Number of function eval. due to Jacobian eval. : 0
Number of error test failures : 4
Number of nonlinear iterations : 101
Number of nonlinear convergence failures : 0
Number of sensitivity evaluations : 104
Number of function eval. due to sensitivity eval. : 0
Number of sensitivity error test failures : 0
Sensitivity options:
Method : SIMULTANEOUS
Difference quotient type : CENTERED
Suppress Sens : False
Solver options:
Solver : CVode
Linear multistep method : BDF
Nonlinear solver : Newton
Linear solver type : DENSE
Maximal order : 5
Tolerances (absolute) : 1e-06
Tolerances (relative) : 1e-06
Simulation interval : 0.0 - 55.0 seconds.
Elapsed simulation time: 0.015174799999998712 seconds.
[20]:
reactor.plot_sens(fig_size=(7, 7))
[20]:
(<Figure size 600x857.143 with 8 Axes>,
array([[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{1, 1}}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{1, 2}}$'>],
[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{1, 3}}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{1, 4}}$'>],
[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{2, 1}}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{2, 2}}$'>],
[<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{2, 3}}$'>,
<AxesSubplot: xlabel='time (s)', ylabel='$\\dfrac{\\partial C_i}{\\partial \\varphi_{2, 4}}$'>]],
dtype=object))

Final fit and correlatiobnb can be analyzed at the converged parameter values by using the ParamInst attribute of the simulation object
[21]:
# Use the ParamInst object to analyze results
sim.ParamInst.plot_parity(fig_size=(6, 6))
sim.ParamInst.plot_correlation()
[21]:
(<Figure size 640x480 with 2 Axes>, <AxesSubplot: >)

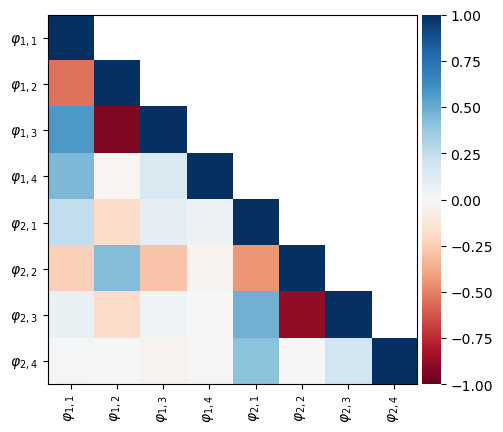
Finally, optimum parameters can be compiled in a pandas dataframe
[22]:
optim_df = pd.DataFrame(np.column_stack((np.log(k_optim), ea_optim/8.314)), columns=('ln(A_optim)', 'ea_optim/R'), index=rxns)
print(optim_df)
ln(A_optim) ea_optim/R
A --> B 23.097013 18160.898475
A --> C 18.960181 16116.934841
B --> C 22.041934 17492.374021
B --> D 19.885501 16041.054422
[ ]: